Discovered – Currently Not Indexed means the link has been added to the queue of things that Googlebot may eventually crawl. Since the web is virtually infinite and there is a prioritization, it may never actually get there.
Crawled – Currently Not Indexed means that the page was downloaded onto Google servers but its contents have not been inserted into the index.
Both Errors i.e. “Discovered – Currently Not Indexed” and “Crawled – Currently Not Indexed” error indicates that Google knows about these such of URLs, but they haven’t crawled (and therefore indexed) them yet.
Websites whose size/audience is small, this issue will be fixed automatically by Google Search Console after re-crawled all URLs by Google.
If you’re encountering the same issue on larger websites (10.000+ pages), this may be caused by the following four reasons:
- Content Overloaded and Poor Content Quality
- Overloaded Server
- Poor Internal Link Structure
- Duplication of Content
Check the troubleshooting steps below to resolve the issue:
To fix this, use Google Cache Checker tool and check if your URL is cached by Google, after that, login to your Google search console and navigate to Coverage Tab (as shown on left side), where you will see 4 tabs i.e. Error, Valid with warning, Valid and Excluded as shown below:
Each status (error, warning valid, valid, excluded) has a specific reason for that status.
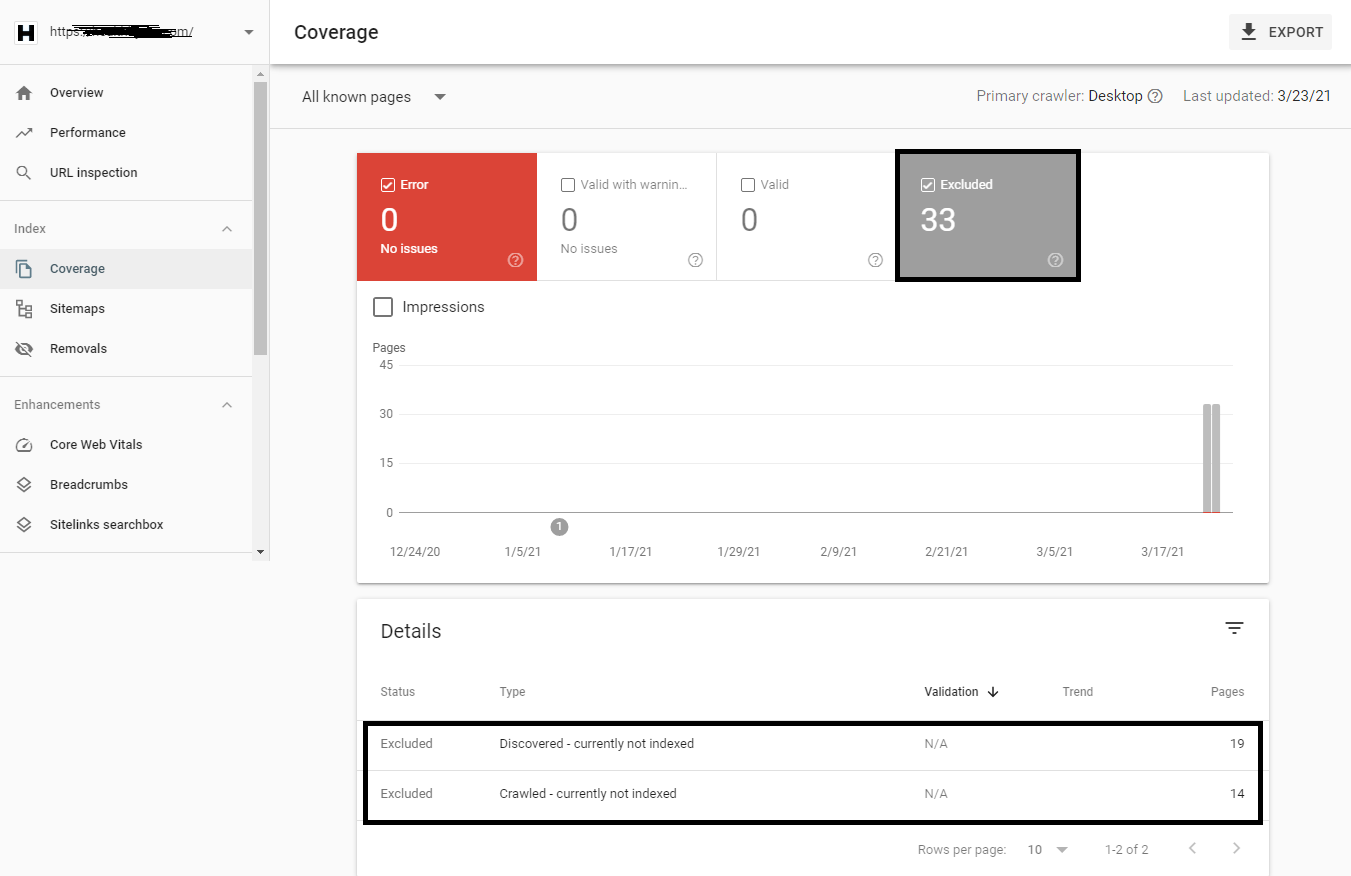
After that, simply click on EXCLUDED tab, where you will see all the details of both i.e. Discovered but not indexed and Crawled but not indexed URL details.
So in our case, as you can see that, there are 19 URLs which are not indexed but all URLs are discovered by Google and 14 URLs which are crawled by Google Search Engine but not indexed.
All these excluded pages are intentionally not indexed by Google and won’t appear in Google Search.
Furthermore, click on a row in the summary page to open a details page for that status + reason combination.
You can see details about the chosen issue by clicking Learn more at the top of the page.
The graph on this page shows the count of affected pages over time and the table shows an example list of pages affected by this status + reason.
You can click the following row elements:
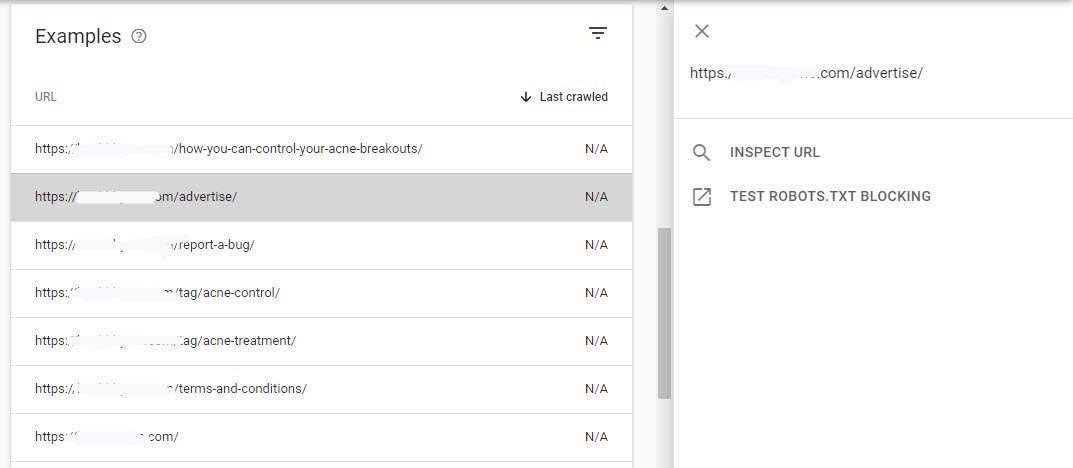
- Click the row to see more details about that URL.
- opens the URL in a new tab.
- opens URL Inspection for that URL.
- copies the URL
Now here you need to click on Inspect URL one at a time. If your green color shows a tick note, it means you don’t need to do anything, Google will automatically index all of your excluded URLs within 24-48 hours but make sure that the URL should not be blocked by your robots.txt file which you can easily check and test by clicking the 2nd option i.e. TEST ROBOTS.TXT BLOCKING option.
So It’s just a part of the process by Google and there is nothing for you to do until you actually get errors.
How To Fix?
- While writing, do not use “ex-crack”, “hack”, “hacking”, “spam” etc keywords in your post.
- Make sure that your article/post should contains at least 1000 words.
- You should post 2-3 articles in a day and do not write too many articles at the same time. If you really want to publish more than 3 articles then make sure that you should schedule your post after every 2-3 hours.
- Always use valid internal and external links in the post and don’t forget to add at least 1 image per article.
- How to Perform Network Security Audits Using Kali Linux
- How to Harden Kali Linux for Maximum Security
- How to Use Python for Ethical Hacking in Kali Linux
- How to Write Bash Scripts in Kali Linux
- 15 Tips to Bring More Traffic to Your Blog
- [Solution] Missing logstash-plain.log File in Logstash
- 8 Essential Tips for Choosing a Domain Name
- Top Fundamental Aspects of SEO That You Need to Understand
- Understanding Netstat – The Network Monitoring Tool
- Using Elasticsearch Ingest Pipeline to Copy Data from One Field to Another